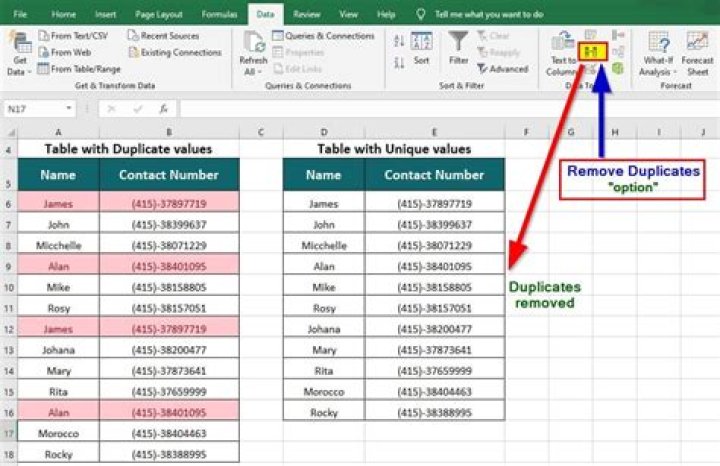
Select the range of cells that has duplicate values you want to remove. Tip: Remove any outlines or subtotals from your data before trying to remove duplicates.Click Data > Remove Duplicates, and then Under Columns, check or uncheck the columns where you want to remove the duplicates. … Click OK.
How do I remove duplicate rows from one column in Python?
Pandas drop_duplicates function has an argument to specify which columns we need to use to identify duplicates. For example, to remove duplicate rows using the column ‘continent’, we can use the argument “subset” and specify the column name we want to identify duplicate.
How do you remove duplicates from a list in Python?
- Method 1: Naïve Method.
- Method 2: Using a list comprehensive.
- Method 3: Using set()
- Method 4: Using list comprehensive + enumerate()
- Method 5: Using collections. OrderedDict. fromkeys()
Does remove duplicates remove the entire row?
Select the range of cells, or ensure that the active cell is in a table. On the Data tab, click Remove Duplicates (in the Data Tools group). … If a duplicate is found in those columns, then the entire row will be removed, including other columns in the table or range.How do I remove duplicate columns from a data frame?
To remove the duplicate columns we can pass the list of duplicate column’s names returned by our API to the dataframe. drop() i.e. It will return a copy of existing DataFrame without duplicate columns.
How does Python handle duplicate rows?
You can remove duplicate rows from a Pandas dataframe using the drop_duplicates function. drop_duplicates function returns a dataframe after removing duplicated rows. By default, the first occurance among the duplicates is retained and others removed. You can change this default behavior by setting the keep parameter.
How do I remove duplicate columns from a DataFrame in Python?
To drop duplicate columns from pandas DataFrame use df. T. drop_duplicates(). T , this removes all columns that have the same data regardless of column names.
How do I remove duplicates but keep rows?
- Select a blank cell next to the data range, D2 for instance, type formula =A3=A2, drag auto fill handle down to the cells you need. …
- Select all data range including the formula cell, and click Data > Filter to enable Filter function.
How do you check for duplicates in Python?
- Add the contents of list in a set. As set contains only unique elements, so no duplicates will be added to the set.
- Compare the size of set and list. If size of list & set is equal then it means no duplicates in list.
- Step 1: Select the range of cells that you want to remove duplicates from. …
- Step 2: After highlighting the block of cells to manipulate, select the “Data “tab on the MS Excel ribbon. …
- Step 3: A dialog with the title Remove Duplicates will appear.
How do you delete a whole row based on duplicates from a single column in Google Sheets?
- Select the dataset from which you want to remove the duplicate records.
- Click the Data option in the menu.
- Click on the Remove Duplicates option.
- In the Remove Duplicates dialog box, make sure ‘Data has header row’ is selected (in case your data has the header row).
How do I remove duplicates from a list?
- Get the ArrayList with duplicate values.
- Create a new List from this ArrayList.
- Using Stream(). distinct() method which return distinct object stream.
- convert this object stream into List.
How do you remove duplicates from a list in a loop in Python?
You can make use of a for-loop that we will traverse the list of items to remove duplicates. The method unique() from Numpy module can help us remove duplicate from the list given. The Pandas module has a unique() method that will give us the unique elements from the list given.
How do I remove duplicates from a string in Python?
- Split input sentence separated by space into words.
- So to get all those strings together first we will join each string in given list of strings.
- Now create a dictionary using Counter method having strings as keys and their frequencies as values.
How do you find duplicates in a column in Python?
Code 1: Find duplicate columns in a DataFrame. To find duplicate columns we need to iterate through all columns of a DataFrame and for each and every column it will search if any other column exists in DataFrame with the same contents already. If yes then that column name will be stored in the duplicate column set.
How do I find duplicate rows in pandas?
Find Duplicate Rows based on all columns To find & select the duplicate all rows based on all columns call the Daraframe. duplicate() without any subset argument. It will return a Boolean series with True at the place of each duplicated rows except their first occurrence (default value of keep argument is ‘first’).
How do you check for duplicates in a DataFrame in Python?
- Syntax : DataFrame.duplicated(subset = None, keep = ‘first’)
- Parameters: subset: This Takes a column or list of column label. …
- keep: This Controls how to consider duplicate value. It has only three distinct value and default is ‘first’.
- Returns: Boolean Series denoting duplicate rows.
How do you delete duplicate rows in PySpark?
- Get Distinct Rows (By Comparing All Columns) …
- PySpark Distinct of Selected Multiple Columns. …
- Source Code to Get Distinct Rows.
How do you treat duplicates in Python?
- Syntax: DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
- Parameters:
- subset: Subset takes a column or list of column label. It’s default value is none. …
- keep: keep is to control how to consider duplicate value.
How would you deal with duplicate values in a data set?
- DataSet: “./Telecom Data Analysis/Complaints.csv”
- Identify overall duplicates in complaints data.
- Create a new dataset by removing overall duplicates in Complaints data.
- Identify duplicates in complaints data based on cust_id.
How can you handle duplicate values in a DataSet for a variable in Python using pandas?
- subset: Takes a column or list of column label. …
- keep: Controls how to consider duplicate value. …
- –> If ‘first’, it considers first value as unique and rest of the same values as duplicate.
- –> If ‘last’, it considers last value as unique and rest of the same values as duplicate.
How do you check for duplicate strings in Python?
- First split given string separated by space.
- Now convert list of words into dictionary using collections. Counter(iterator) method. Dictionary contains words as key and it’s frequency as value.
- Now traverse list of words again and check which first word has frequency greater than 1.
What are duplicates in Python?
If an integer or string or any items in a list are repeated more than one time, they are duplicates.
Can set have duplicates in Python?
Sets cannot contain duplicates. Duplicates are discarded when initializing a set. If adding an element to a set, and that element is already contained in the set, then the set will not change.
Does remove duplicates remove both?
Generally, when you remove duplicates in Excel, the first occurrence of each duplicate will be kept, and all others will be deleted. Another valuable task is to remove both (or all) duplicate rows. This can be achieved using a combination of the IF and COUNTIF Functions and the Go To Special feature.
How do I remove duplicates in multiple columns?
- Select the data.
- Go to Data –> Data Tools –> Remove Duplicates.
- In the Remove Duplicates dialog box: If your data has headers, make sure the ‘My data has headers’ option is checked. Select all the columns except the Date column.
How do I eliminate duplicate rows in Excel and keep the highest value?
(1) Select Fruit column (which you will remove duplicates rows by), and then click the Primary Key button; (2) Select the Amount column (Which you will keep highest values in), and then click Calculate > Max. (3) Specify combination rules for other columns as you need.
How do I drop duplicates in pandas?
Dropping duplicate rows We can use Pandas built-in method drop_duplicates() to drop duplicate rows. Note that we started out as 80 rows, now it’s 77. By default, this method returns a new DataFrame with duplicate rows removed. We can set the argument inplace=True to remove duplicates from the original DataFrame.
How do I remove duplicates in LibreOffice?
- Select a range of cells or entire columns containing duplicates.
- Select the menu item Data > More Filters > Standard Filter.
- Set the filter rule: “ColumnA = Not empty”.
- Expand Options, and check (enable) the box “No duplications”.
- Click OK to execute the filter.
How can I delete empty rows in Excel?
You can remove blank rows in Excel by first doing a “Find & Select” of blank rows in the document. You can then delete them all at once using the “Delete” button on the Home tab.
How do I hide duplicate rows in Excel?
On the Data menu, point to Filter, and then click Advanced Filter. In the Advanced Filter dialog box, click Filter the list, in place. Select the Unique records only check box, and then click OK. The filtered list is displayed and the duplicate rows are hidden.